1. Installation
1.1. Requirements
Nextflow can be used on any POSIX compatible system (Linux, OS X, etc). It requires Bash and Java 8 (or later) to be installed.
Optional requirements:
-
Docker engine 1.10.x (or later)
-
Singularity 2.5.x (or later, optional)
-
Conda 4.5 (or later, optional)
-
Graphviz (optional)
-
AWS Batch computing environment properly configured (optional)
1.2. Nextflow Installation
Nextflow is distributed as a self-contained executable package, which means that it does not require any special installation procedure.
It only needs two easy steps:
-
Download the executable package by using the command shown below. It will create the
nextflowmain executable file in the current directory.curl https://get.nextflow.io | bash -
Finally, move the
nextflowfile to a directory accessible by your$PATHvariable (this is only required to avoid remembering and typing the full path tonextfloweach time you need to run it).mv nextflow ~/bin -
Check everything is fine running the command:
nextflow info
|
Alternatively Nextflow can also be installed using Conda package managed using the command: |
2. Simple Rna-Seq pipeline
During this tutorial you will implement a proof of concept of a RNA-Seq pipeline which:
-
Indexes a trascriptome file.
-
Performs quality controls
-
Performs quantification.
-
Create a MultiqQC report.
Change in the course directory with the following command:
cd ~/nf-hack18/course2.1. Define the pipeline parameters
The script script1.nf defines the pipeline input parameters.
1
2
3
4
5
params.reads = "$baseDir/data/ggal/*_{1,2}.fq"
params.transcriptome = "$baseDir/data/ggal/transcriptome.fa"
params.multiqc = "$baseDir/multiqc"
println "reads: $params.reads"
Run it by using the following command:
nextflow run script1.nfTry to specify a different input parameter, for example:
nextflow run script1.nf --reads this/and/that2.1.1. Exercise
Modify the script1.nf adding a fourth parameter named outdir and set it to a default path
that will be used as the pipeline output directory.
2.1.2. Exercise
Modify the script1.nf to print all the pipeline parameters by using a single println command and a multiline string statement.
| see an example here. |
2.1.3. Recap
In this step you have learned:
-
How to define parameters in your pipeline script
-
How to pass parameters by using the command line
-
The use of
$varand${var}variable placeholders -
How to use multiline strings
2.2. Create transcriptome index file
Nextflow allows the execution of any command or user script by using a process definition.
A process is defined by providing three main declarations: the process inputs, the process outputs and finally the command script.
The second example adds the index process.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
/*
* pipeline input parameters
*/
params.reads = "$baseDir/data/ggal/*_{1,2}.fq"
params.transcriptome = "$baseDir/data/ggal/transcriptome.fa"
params.multiqc = "$baseDir/multiqc"
params.outdir = "results"
println """\
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: ${params.transcriptome}
reads : ${params.reads}
outdir : ${params.outdir}
"""
.stripIndent()
/*
* create a transcriptome file object given then transcriptome string parameter
*/
transcriptome_file = file(params.transcriptome)
/*
* define the `index` process that create a binary index
* given the transcriptome file
*/
process index {
input:
file transcriptome from transcriptome_file
output:
file 'index' into index_ch
script:
"""
salmon index --threads $task.cpus -t $transcriptome -i index
"""
}
It takes the transcriptome file as input and creates the transcriptome index by using the salmon tool.
Note how the input declaration defines a transcriptome variable in the process context
that it is used in the command script to reference that file in the Salmon command line.
Try to run it by using the command:
nextflow run script2.nfThe execution will fail because Salmon is not installed in your environment.
Add the command line option -with-docker to launch the execution through a Docker container
as shown below:
nextflow run script2.nf -with-dockerThis time it works because it uses the Docker container nextflow/rnaseq-nf defined in the
nextflow.config file.
In order to avoid to add the option -with-docker add the following line in the nextflow.config file:
docker.enabled = true2.2.1. Exercise
Enable the Docker execution by default adding the above setting in the nextflow.config file.
2.2.2. Exercise
Print the output of the index_ch channel by using the println
operator (do not confuse it with the println statement seen previously).
2.2.3. Exercise
Use the command tree work to see how Nextflow organises the process work directory.
2.2.4. Recap
In this step you have learned:
-
How to define a process executing a custom command
-
How process inputs are declared
-
How process outputs are declared
-
How to access the number of available CPUs
-
How to print the content of a channel
2.3. Collect read files by pairs
This step shows how to match read files into pairs, so they can be mapped by Salmon.
Edit the script script3.nf and add the following statement as the last line:
read_pairs_ch.println()Save it and execute it with the following command:
nextflow run script3.nfIt will print an output similar to the one shown below:
[ggal_gut, [/.../data/ggal/gut_1.fq, /.../data/ggal/gut_2.fq]]
The above example shows how the read_pairs_ch channel emits tuples composed by
two elements, where the first is the read pair prefix and the second is a list
representing the actual files.
Try it again specifying different read files by using a glob pattern:
nextflow run script3.nf --reads 'data/ggal/*_{1,2}.fq'
File paths including one or more wildcards ie. *, ?, etc. MUST be
wrapped in single-quoted characters to avoid Bash expands the glob.
|
2.3.1. Exercise
Use the set operator in place
of = assignment to define the read_pairs_ch channel.
2.3.2. Exercise
Use the ifEmpty operator
to check if the read_pairs_ch contains at least an item.
2.3.3. Recap
In this step you have learned:
-
How to use
fromFilePairsto handle read pair files -
How to use the
setoperator to define a new channel variable -
How to use the
ifEmptyoperator to check if a channel is empty
2.4. Perform expression quantification
The script script4.nf adds the quantification process.
In this script note as the index_ch channel, declared as output in the index process,
is now used as a channel in the input section.
Also note as the second input is declared as a set composed by two elements:
the pair_id and the reads in order to match the structure of the items emitted
by the read_pairs_ch channel.
Execute it by using the following command:
nextflow run script4.nf -resumeYou will see the execution of the quantification process.
The -resume option cause the execution of any step that has been already processed to be skipped.
Try to execute it with more read files as shown below:
nextflow run script4.nf -resume --reads 'data/ggal/*_{1,2}.fq'You will notice that the quantification process is executed more than
one time.
Nextflow parallelizes the execution of your pipeline simply by providing multiple input data to your script.
2.4.1. Exercise
Add a tag directive to the
quantification process to provide a more readable execution log.
2.4.2. Exercise
Add a publishDir directive
to the quantification process to store the process results into a directory of your choice.
2.4.3. Recap
In this step you have learned:
-
How to connect two processes by using the channel declarations
-
How to resume the script execution skipping already already computed steps
-
How to use the
tagdirective to provide a more readable execution output -
How to use the
publishDirto store a process results in a path of your choice
2.5. Quality control
This step implements a quality control of your input reads. The inputs are the same
read pairs which are provided to the quantification steps
You can run it by using the following command:
nextflow run script5.nf -resumeThe script will report the following error message:
Channel `read_pairs_ch` has been used twice as an input by process `fastqc` and process `quantification`
2.5.1. Exercise
Modify the creation of the read_pairs_ch channel by using a into
operator in place of a set.
| see an example here. |
2.5.2. Recap
In this step you have learned:
-
How to use the
intooperator to create multiple copies of the same channel
2.6. MultiQC report
This step collect the outputs from the quantification and fastqc steps to create
a final report by using the MultiQC tool.
Execute the script with the following command:
nextflow run script6.nf -resume --reads 'data/ggal/*_{1,2}.fq'It creates the final report in the results folder in the current work directory.
In this script note the use of the mix
and collect operators chained
together to get all the outputs of the quantification and fastqc process as a single
input.
2.6.1. Recap
In this step you have learned:
-
How to collect many outputs to a single input with the
collectoperator -
How to
mixtwo channels in a single channel -
How to chain two or more operators togethers
2.7. Handle completion event
This step shows how to execute an action when the pipeline completes the execution.
Note that Nextflow processes define the execution of asynchronous tasks i.e. they are not executed one after another as they are written in the pipeline script as it would happen in a common imperative programming language.
The script uses the workflow.onComplete event handler to print a confirmation message
when the script completes.
1
2
3
workflow.onComplete {
println ( workflow.success ? "\nDone! Open the following report in your browser --> $params.outdir/multiqc_report.html\n" : "Oops .. something went wrong" )
}
Try to run it by using the following command:
nextflow run script7.nf -resume --reads 'data/ggal/*_{1,2}.fq'2.8. Custom scripts
Real world pipelines use a lot of custom user scripts (BASH, R, Python, etc). Nextflow
allows you to use and manage all these scripts in consistent manner. Simply put them
in a directory named bin in the pipeline project root. They will be automatically added
to the pipeline execution PATH.
For example, create a file named fastqc.sh with the following content:
1
2
3
4
5
6
7
8
9
#!/bin/bash
set -e
set -u
sample_id=${1}
reads=${2}
mkdir fastqc_${sample_id}_logs
fastqc -o fastqc_${sample_id}_logs -f fastq -q ${reads}
Save it, give execute permission and move it in the bin directory as shown below:
1
2
3
chmod +x fastqc.sh
mkdir -p bin
mv fastqc.sh bin
Then, open the script7.nf file and replace the fastqc process' script with
the following code:
1
2
3
4
script:
"""
fastqc.sh "$sample_id" "$reads"
"""
Run it as before:
nextflow run script7.nf -resume --reads 'data/ggal/*_{1,2}.fq'2.8.1. Recap
In this step you have learned:
-
How to write or use existing custom script in your Nextflow pipeline.
-
How to avoid the use of absolute paths having your scripts in the
bin/project folder.
2.9. Mail notification
Send a notification email when the workflow execution complete using the -N <email address>
command line option. Execute again the previous example specifying your email address:
nextflow run script7.nf -resume --reads 'data/ggal/*_{1,2}.fq' -N <your email>
Your computer must have installed a pre-configured mail tool, such as mail or sendmail.
|
Alternatively you can provide the settings of the STMP server needed to send the mail notification in the Nextflow config file. See mail documentation for details.
2.10. More resources
-
Nextflow documentation - The Nextflow docs home.
-
Nextflow patterns - A collection of Nextflow implementation patterns.
-
CalliNGS-NF - An Variant calling pipeline implementing GATK best practices.
-
nf-core - A community collection of production ready genomic pipelines.
3. Bonus
3.1. Run a pipeline from a GitHub repository
Nextflow allows the execution of a pipeline project directly from a GitHub repository (or similar services eg. BitBucket and GitLab).
This simplifies the sharing and the deployment of complex projects and tracking changes in a consistent manner.
The following GitHub repository hosts a complete version of the workflow introduced in this tutorial:
You can run it by specifying the project name as shown below:
nextflow run nextflow-io/rnaseq-nf -with-dockerIt automatically downloads it and store in the $HOME/.nextflow folder.
Use the command info to show the project information, e.g.:
nextflow info nextflow-io/rnaseq-nfNextflow allows the execution of a specific revision of your project by using the -r command line option. For Example:
nextflow run nextflow-io/rnaseq-nf -r devRevision are defined by using Git tags or branches defined in the project repository.
This allows a precise control of the changes in your project files and dependencies over time.
3.2. Metrics and reports
Nextflow is able to produce multiple reports and charts providing several runtime metrics and execution information.
Run the rnaseq-nf pipeline previously introduced as shown below:
nextflow run -r master rnaseq-nf -with-docker -with-report -with-trace -with-timeline -with-dag dag.pngThe -with-report option enables the creation of the workflow execution report. Open
the file report.html with a browser to see the report created with the above command.
The -with-trace option enables the create of a tab separated file containing runtime
information for each executed task. Check the content of the file trace.txt for an example.
The -with-timeline option enables the creation of the workflow timeline report showing
how processes where executed along time. This may be useful to identify most time consuming
tasks and bottlenecks. See an example at this link.
Finally the -with-dag option enables to rendering of the workflow execution direct acyclic graph
representation. Note: this feature requires the installation of Graphviz in your computer.
See here for details.
The public IP address of your computer can be obtained with the command myip.
|
Note: runtime metrics may be incomplete for run short running tasks as in the case of this tutorial.
4. Basic language structures and commands
Nextflow is a DSL implemented on top of the Groovy programming lang, which in turns is a super-set of the Java programming language. This means that Nextflow can run any Groovy and Java code.
4.1. Printing values
To print something is as easy as using one of the print or println methods.
1
println("Hello, World!")
The only difference between the two is that the println method implicitly appends a new line character to the printed string.
| parenthesis for function invocations are optional. Therefore also the following is a valid syntax. |
1
println "Hello, World!"
4.2. Comments
Comments use the same syntax as in the C-family programming languages:
1
2
3
4
5
6
// comment a single config file
/*
a comment spanning
multiple lines
*/
4.3. Variables
To define a variable, simply assign a value to it:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
x = 1
println x
x = new java.util.Date()
println x
x = -3.1499392
println x
x = false
println x
x = "Hi"
println x
Local variables are defined using the def keyword:
1
def x = 'foo'
It should be always used when defining variables local to a function or a closure.
4.4. Lists
A List object can be defined by placing the list items in square brackets:
1
list = [10,20,30,40]
You can access a given item in the list with square-bracket notation (indexes start at 0)
or using the get method:
1
2
assert list[0] == 10
assert list[0] == list.get(0)
In order to get the length of the list use the size method:
1
assert list.size() == 4
Lists can also be indexed with negative indexes and reversed ranges.
1
2
3
list = [0,1,2]
assert list[-1] == 2
assert list[-1..0] == list.reverse()
List objects implements all methods provided by the Java java.util.List interface plus the extension methods provided by Groovy API.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
assert [1,2,3] << 1 == [1,2,3,1]
assert [1,2,3] + [1] == [1,2,3,1]
assert [1,2,3,1] - [1] == [2,3]
assert [1,2,3] * 2 == [1,2,3,1,2,3]
assert [1,[2,3]].flatten() == [1,2,3]
assert [1,2,3].reverse() == [3,2,1]
assert [1,2,3].collect{ it+3 } == [4,5,6]
assert [1,2,3,1].unique().size() == 3
assert [1,2,3,1].count(1) == 2
assert [1,2,3,4].min() == 1
assert [1,2,3,4].max() == 4
assert [1,2,3,4].sum() == 10
assert [4,2,1,3].sort() == [1,2,3,4]
assert [4,2,1,3].find{it%2 == 0} == 4
assert [4,2,1,3].findAll{it%2 == 0} == [4,2]
4.5. Maps
Maps are like lists that have an arbitrary type of key instead of integer. Therefore, the syntax is very much aligned.
1
map = [a:0, b:1, c:2]
Maps can be accessed in a conventional square-bracket syntax or as if the key was a property of the map.
1
2
3
assert map['a'] == 0 (1)
assert map.b == 1 (2)
assert map.get('c') == 2 (3)
| 1 | Use of the square brackets. |
| 2 | Use a dot notation. |
| 3 | Use of get method. |
To add data or to modify a map, the syntax is similar to adding values to list:
1
2
3
4
map['a'] = 'x' (1)
map.b = 'y' (2)
map.put('c', 'z') (3)
assert map == [a:'x', b:'y', c:'z']
| 1 | Use of the square brackets. |
| 2 | Use a dot notation. |
| 3 | Use of get method. |
Map objects implements all methods provided by the Java java.util.Map interface plus the extension methods provided by Groovy API.
4.6. String interpolation
String literals can be defined enclosing them either with single-quoted or double-quotes characters.
Double-quoted strings can contain the value of an arbitrary variable by prefixing its name with the $ character, or the value of any expression by using the ${expression} syntax, similar to Bash/shell scripts:
1
2
3
4
5
6
foxtype = 'quick'
foxcolor = ['b', 'r', 'o', 'w', 'n']
println "The $foxtype ${foxcolor.join()} fox"
x = 'Hello'
println '$x + $y'
This code prints:
1
2
The quick brown fox
$x + $y
Note the different use of $ and ${..} syntax to interpolate value expressions in a string literal.
|
Finally string literals can also be defined using the / character as delimiter. They are known as
slashy strings and are useful for defining regular expressions and patterns, as there is no need to escape backslashes. As with double quote strings they allow to interpolate variables prefixed with a $
character.
Try the following to see the difference:
1
2
3
4
5
x = /tic\tac\toe/
y = 'tic\tac\toe'
println x
println y
it prints:
tic\tac\toe
tic ac oe4.7. Multi-line strings
A block of text that span multiple lines can be defined by delimiting it with triple single or double quotes:
1
2
3
4
text = """
Hello there James
how are you today?
"""
Finally multi-line strings can also be defined with slashy string. For example:
1
2
3
4
5
text = /
This is a multi-line
slashy string!
It's cool, isn't it?!
/
| Like before, multi-line strings inside double quotes and slash characters support variable interpolation, while single-quoted multi-line strings do not. |
4.8. If statement
The if statement uses the same syntax common other programming lang such Java, C, JavaScript, etc.
1
2
3
4
5
6
if( < boolean expression > ) {
// true branch
}
else {
// false branch
}
The else branch is optional. Also curly brackets are optional when the branch define just a single
statement.
1
2
3
x = 1
if( x > 10 )
println 'Hello'
null, empty strings and empty collections are evaluated to false.
|
Therefore a statement like:
1
2
3
4
5
6
7
list = [1,2,3]
if( list != null && list.size() > 0 ) {
println list
}
else {
println 'The list is empty'
}
Can be written as:
1
2
3
4
if( list )
println list
else
println 'The list is empty'
See the Groovy-Truth for details.
In some cases can be useful to replace if statement with a ternary expression aka
conditional expression. For example:
|
1
println list ? list : 'The list is empty'
The previous statement can be further simplified using the Elvis operator as shown below:
1
println list ?: 'The list is empty'
4.9. For statement
The classical for loop syntax is supported as shown here:
1
2
3
for (int i = 0; i <3; i++) {
println("Hello World $i")
}
Iteration over list objects is also possible using the syntax below:
1
2
3
4
5
list = ['a','b','c']
for( String elem : list ) {
println elem
}
4.10. Functions
It is possible to define a custom function into a script, as shown here:
1
2
3
4
5
int fib(int n) {
return n < 2 ? 1 : fib(n-1) + fib(n-2)
}
assert fib(10)==89
A function can take multiple arguments separating them with a comma. The return
keyword can be omitted and the function implicitly returns the value
of the last evaluated expression. Also explicit types can be omitted (thought not recommended):
1
2
3
4
5
def fact( n ) {
n > 1 ? n * fact(n-1) : 1
}
assert fact(5) == 120
4.11. Closures
Closures are the swiss army knife of Nextflow/Groovy programming. In a nutshell a closure is is a block of code that can be passed as an argument to a function, it could also be defined an anonymous function.
More formally, a closure allows the definition of functions as first class objects.
1
square = { it * it }
The curly brackets around the expression it * it tells the script interpreter to treat this expression as code. The it identifier is an implicit variable that represents the value that is passed to the function when it is invoked.
Once compiled the function object is assigned to the variable square as any other variable assignments shown previously. To invoke the closure execution use the special method call or just use the round
parentheses to specify the closure parameter(s). For example:
1
2
assert square.call(5) == 25
assert square(9) == 81
This is not very interesting until we find that we can pass the function square as an argument to other functions or methods.
Some built-in functions take a function like this as an argument. One example is the collect method on lists:
1
2
x = [ 1, 2, 3, 4 ].collect(square)
println x
It prints:
[ 1, 4, 9, 16 ]By default, closures take a single parameter called it, to give it a different name use the
-> syntax. For example:
1
square = { num -> num * num }
It’s also possible to define closures with multiple, custom-named parameters.
For example, the method each() when applied to a map can take a closure with two arguments,
to which it passes the key-value pair for each entry in the map object. For example:
1
2
3
4
5
printMap = { a, b ->
println "$a with value $b"
}
[ "Yue" : "Wu", "Mark" : "Williams", "Sudha" : "Kumari" ].each(printMap)
It prints:
Yue with value Wu
Mark with value Williams
Sudha with value KumariA closure has two other important features. First, it can access and modify variables in the scope where it is defined.
Second, a closure can be defined in an anonymous manner, meaning that it is not given a name, and is defined in the place where it needs to be used.
As an example showing both these features, see the following code fragment:
1
2
3
4
result = 0 (1)
map = ["China": 1 , "India" : 2, "USA" : 3] (2)
map.keySet().each { result+= myMap[it] } (3)
println result
| 1 | Define a global variable. |
| 2 | Define a map object. |
| 3 | Invoke the each method passing closure object which modifies the result variable. |
Learn more about closures in the Groovy documentation.
4.12. More resources
The complete Groovy language documentation is available at this link.
A great resource to master Apache Groovy syntax is Groovy in Action.
5. Channels
Channels are a key data structure of Nextflow that allows the implementation of reactive-functional oriented computational workflows based on the Dataflow programming paradigm.
They are used to logically connect tasks each other or to implement functional style data transformations.
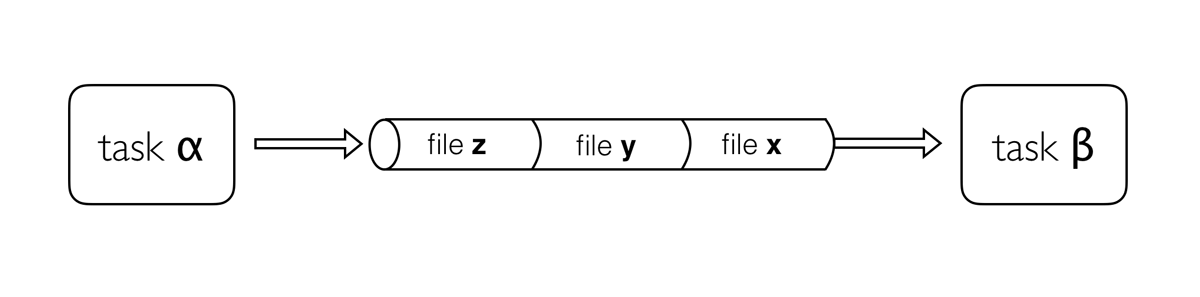
5.1. Channel types
Nextflow distinguish two different kinds of channels: queue channels and value channels.
5.1.1. Queue channel
A queue channel is a asynchronous unidirectional FIFO queue which connects two processes or operators.
-
What asynchronous means? That operations are non-blocking.
-
What unidirectional means? That data flow from a producer to a consumer.
-
What FIFO means? That the data is guaranteed to be delivered in the same order as it is produced.
A queue channel is implicitly created by process output definitions or using channel factories methods such as Channel.from or Channel.fromPath.
Try the following snippets:
1
2
3
p = Channel.from(1,2,3)
println(p) (1)
p.println() (2)
Note the different use of println:
| 1 | Use the built-in pritnln function to print the p variable. |
| 2 | Apply the println method to the p channel, therefore prints each item emitted by the channels. |
Exercise
Try to execute this snippet, it will produce an error message.
1
2
3
p = Channel.from(1,2,3)
p.println()
p.println()
| A queue channel can have one and exactly one producer and one and exactly one consumer. |
5.1.2. Value channels
A value channel a.k.a. singleton channel by definition is bound to a single value and it can be read unlimited times without consuming its content.
1
2
3
4
p = Channel.value('Hello')
p.println()
p.println()
p.println()
It prints:
Hello
Hello
Hello5.2. Channel factories
5.2.1. value
The value factory method is used to create a value channel. An optional not null argument
can be specified to bind the channel to a specific value. For example:
1
2
3
ch1 = Channel.value() (1)
ch2 = Channel.value( 'Hello there' ) (2)
ch2 = Channel.value( [1,2,3,4,5] ) (3)
| 1 | Creates an empty value channel. |
| 2 | Creates a value channel and binds a string to it. |
| 3 | Creates a value channel and binds a list object to it that will be emitted as a sole emission. |
5.2.2. from
The factory Channel.from allows the creation of a queue channel with the values specified as argument.
1
2
ch = Channel.from( 1, 3, 5, 7 )
ch.println{ "value: $it" }
The first line in this example creates a variable ch which holds a channel object. This channel emits the values specified as a parameter in the from method. Thus the second line will print the following:
value: 1 value: 3 value: 5 value: 7
5.2.3. fromPath
The fromPath factory method create a queue channel emitting one or more files
matching the specified glob pattern.
1
Channel.fromPath( '/data/big/*.txt' )
This example creates a channel and emits as many items as there are files with txt extension in the /data/big folder. Each element is a file object implementing the Path interface.
Two asterisks, i.e. **, works like * but crosses directory boundaries. This syntax is generally used for matching complete paths. Curly brackets specify a collection of sub-patterns.
|
| Name | Description |
|---|---|
glob |
When |
type |
Type of paths returned, either |
hidden |
When |
maxDepth |
Maximum number of directory levels to visit (default: |
followLinks |
When |
relative |
When |
checkIfExists |
When |
Learn more about the blog pattern syntax at this link.
Exercise
Use the Channel.fromPath method to create a channel emitting all files with the suffix .fq in the data/ggal/ and any subdirectory, then print the file name.
5.2.4. fromFilePairs
The fromFilePairs method creates a channel emitting the file pairs matching a glob pattern provided by the user. The matching files are emitted as tuples in which the first element is the grouping key of the matching pair and the second element is the list of files (sorted in lexicographical order).
1
2
3
Channel
.fromFilePairs('/my/data/SRR*_{1,2}.fastq')
.println()
It will produce an output similar to the following:
[SRR493366, [/my/data/SRR493366_1.fastq, /my/data/SRR493366_2.fastq]]
[SRR493367, [/my/data/SRR493367_1.fastq, /my/data/SRR493367_2.fastq]]
[SRR493368, [/my/data/SRR493368_1.fastq, /my/data/SRR493368_2.fastq]]
[SRR493369, [/my/data/SRR493369_1.fastq, /my/data/SRR493369_2.fastq]]
[SRR493370, [/my/data/SRR493370_1.fastq, /my/data/SRR493370_2.fastq]]
[SRR493371, [/my/data/SRR493371_1.fastq, /my/data/SRR493371_2.fastq]]| The glob pattern must contain at least a star wildcard character. |
| Name | Description |
|---|---|
type |
Type of paths returned, either |
hidden |
When |
maxDepth |
Maximum number of directory levels to visit (default: |
followLinks |
When |
size |
Defines the number of files each emitted item is expected to hold (default: 2). Set to |
flat |
When |
checkIfExists |
When |
Exercise
Use the fromFilePairs method to create a channel emitting all pairs of fastq read in the data/ggal/
directory and print them.
Then use the flat:true option and compare the output with the previous execution.
6. Operators
-
Built-in functions applied to channels
-
Transform channels content
-
Can be used also to filter, fork and combine channels
6.1. Basic example
1
2
3
nums = Channel.from(1,2,3,4) (1)
square = nums.map { it -> it * it } (2)
square.println() (3)
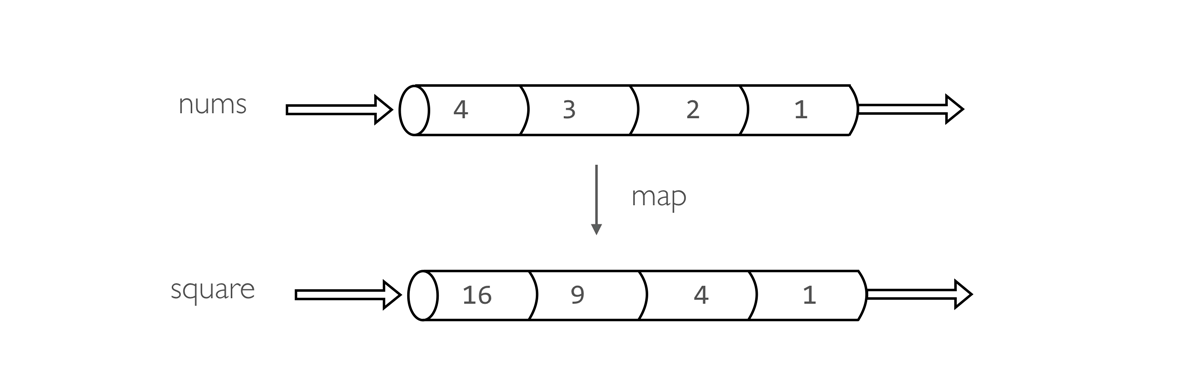
| 1 | Create a queue channel emitting four values. |
| 2 | Create a new channels transforming each number in it’s square. |
| 3 | Print the channel content. |
Operators can be chained to implement custom behaviors:
1
2
3
Channel.from(1,2,3,4)
.map { it -> it * it }
.println()
Operators can be separated in to five groups:
-
Filtering operators
-
Transforming operators
-
Splitting operators
-
Combining operators
-
Forking operators
-
Maths operators
6.2. Basic operators
6.2.1. println
The println operator prints the items emitted by a channel to the console standard output appending a
new line character to each of them. For example:
1
2
3
Channel
.from('foo', 'bar', 'baz', 'qux')
.println()
It prints:
foo
bar
baz
quxAn optional closure parameter can be specified to customise how items are printed. For example:
1
2
3
Channel
.from('foo', 'bar', 'baz', 'qux')
.println { "- $it" }
It prints:
- foo - bar - baz - qux
println is a terminal operator, i.e. it does not allow the chaining with other operators.
|
6.2.2. map
The map operator applies a function of your choosing to every item emitted by a channel, and returns the items so obtained as a new channel. The function applied is called the mapping function and is expressed with a closure as shown in the example below:
1
2
3
4
Channel
.from( 'hello', 'world' )
.map { it -> it.reverse() }
.println()
A map can associate to each element a generic tuple containing any data as needed.
1
2
3
4
Channel
.from( 'hello', 'world' )
.map { word -> [word, word.size()] }
.println { word, len -> "$word contains $len letters" }
Exercise
Use fromPath to create a channel emitting the fastq files matching the pattern data/ggal/*.fq,
then chain with a map to return a pair containing the file name and the path itself.
Finally print the resulting channel.
1
2
3
Channel.fromPath('data/ggal/*.fq')
.map { file -> [ file.name, file ] }
.println { name, file -> "> file: $name" }
6.2.3. into
The into operator connects a source channel to two or more target channels in such a way the values emitted by the source channel are copied to the target channels. For example:
1
2
3
4
5
6
Channel
.from( 'a', 'b', 'c' )
.into{ foo; bar }
foo.println{ "Foo emits: " + it }
bar.println{ "Bar emits: " + it }
Note the use in this example of curly brackets and the ; as channel names separator. This is needed because the actual parameter of into is a closure which defines the target channels to which the source one is connected.
|
6.2.4. mix
The mix operator combines the items emitted by two (or more) channels into a single channel.
1
2
3
4
5
c1 = Channel.from( 1,2,3 )
c2 = Channel.from( 'a','b' )
c3 = Channel.from( 'z' )
c1 .mix(c2,c3).println()
1
2
a
3
b
z
The items in the resulting channel have the same order as in respective original channel,
however there’s no guarantee that the element of the second channel are append after the elements
of the first. Indeed in the above example the element a has been printed before 3.
|
6.2.5. flatten
The flatten operator transforms a channel in such a way that every tuple is flattened so that each single entry is emitted as a sole element by the resulting channel.
1
2
3
4
5
6
7
foo = [1,2,3]
bar = [4, 5, 6]
Channel
.from(foo, bar)
.flatten()
.println()
The above snippet prints:
1
2
3
4
5
66.2.6. collect
The collect operator collects all the items emitted by a channel to a list and return the resulting object as a sole emission.
1
2
3
4
Channel
.from( 1, 2, 3, 4 )
.collect()
.println()
It prints a single value:
[1,2,3,4]
The result of the collect operator is a value channel.
|
6.2.7. groupTuple
The groupTuple operator collects tuples (or lists) of values emitted by the source channel grouping together the elements that share the same key. Finally it emits a new tuple object for each distinct key collected.
Try the following example:
1
2
3
4
Channel
.from( [1,'A'], [1,'B'], [2,'C'], [3, 'B'], [1,'C'], [2, 'A'], [3, 'D'] )
.groupTuple()
.println()
It shows:
[1, [A, B, C]]
[2, [C, A]]
[3, [B, D]]This operator is useful to process altogether all elements for which there’s a common property or a grouping key.
Exercise
Use fromPath to create a channel emitting the fastq files matching the pattern data/ggal/*.fq,
then use a map to associate to each file the name prefix. Finally group together all
files having the same common prefix.
6.2.8. join
The join operator creates a channel that joins together the items emitted by two channels for which exits a matching key. The key is defined, by default, as the first element in each item emitted.
1
2
3
left = Channel.from(['X', 1], ['Y', 2], ['Z', 3], ['P', 7])
right= Channel.from(['Z', 6], ['Y', 5], ['X', 4])
left.join(right).println()
The resulting channel emits:
[Z, 3, 6]
[Y, 2, 5]
[X, 1, 4]6.2.9. subscribe
The subscribe operator permits to execute a user define function each time a new value is emitted by the source channel.
The emitted value is passed implicitly to the specified function. For example:
1
2
3
4
5
// define a channel emitting three values
source = Channel.from ( 'alpha', 'beta', 'delta' )
// subscribe a function to the channel printing the emitted values
source.subscribe { println "Got: $it" }
It prints:
Got: alpha Got: beta Got: delta
subscribe is a terminal operator, i.e. it does not allow the chaining with other operators.
|
6.3. More resources
Check the operators documentation on Nextflow web site.
7. Processes
A process is the basic Nextflow computing primitive to execute foreign function i.e. custom scripts or tools.
The process definition starts with keyword the process, followed by process name and finally the process body delimited by curly brackets. The process body must contain a string which represents the command or, more generally, a script that is executed by it.
A basic process looks like the following example:
1
2
3
4
5
process sayHello {
"""
echo 'Hello world!'
"""
}
A process may contain five definition blocks, respectively: directives, inputs, outputs, when clause and finally the process script. The syntax is defined as follows:
process < name > {
[ directives ] (1)
input: (2)
< process inputs >
output: (3)
< process outputs >
when: (4)
< condition >
[script|shell|exec]: (5)
< user script to be executed >
}
| 1 | Zero, one or more process directives |
| 2 | Zero, one or more process inputs |
| 3 | Zero, one or more process outputs |
| 4 | An optional boolean conditional to trigger the process execution |
| 5 | The command to be executed |
7.1. Script
The script block is a string statement that defines the command that is executed by the process to carry out its task.
A process contains one and only one script block, and it must be the last statement when the process contains input and output declarations.
The script block can be a simple string or multi-line string. The latter simplifies the writing of non trivial scripts composed by multiple commands spanning over multiple lines. For example::
1
2
3
4
5
6
7
8
process example {
script:
"""
blastp -db /data/blast -query query.fa -outfmt 6 > blast_result
cat blast_result | head -n 10 | cut -f 2 > top_hits
blastdbcmd -db /data/blast -entry_batch top_hits > sequences
"""
}
By default the process command is interpreted as a Bash script. However any other scripting language can be used just simply starting the script with the corresponding Shebang declaration. For example:
1
2
3
4
5
6
7
8
9
10
process pyStuff {
script:
"""
#!/usr/bin/env python
x = 'Hello'
y = 'world!'
print "%s - %s" % (x,y)
"""
}
| This allows the compositing in the same workflow script of tasks using different programming languages which may better fit a particular job. However for large chunks of code is suggested to save them into separate files and invoke them from the process script. |
7.1.1. Script variables
Process script can be defined dynamically using variable values like in other string.
1
2
3
4
5
6
7
8
params.data = 'World'
process foo {
script:
"""
echo Hello $params.data
"""
}
Since Nextflow uses the same Bash syntax for variable substitutions in strings, Bash environment variables need to be escaped using \ character.
|
1
2
3
4
5
6
process foo {
script:
"""
echo \$PATH | tr : '\\n'
"""
}
This can be tricky when the script uses many Bash variables. A possible alternative is to use a script string delimited by single-quote characters
1
2
3
4
5
6
process bar {
script:
'''
echo $PATH | tr : '\\n'
'''
}
However this won’t allow any more the usage of Nextflow variables in the command script.
Another alternative is to use a shell statement instead of script which uses a different
syntax for Nextflow variable: !{..}. This allow to use both Nextflow and Bash variables in
the same script.
1
2
3
4
5
6
7
8
9
params.data = 'le monde'
process baz {
shell:
'''
X='Bonjour'
echo $X !{params.data}
'''
}
Exercise
Write a Nextflow script, putting together the above example, printing either a Nextflow variables and a Bash variable both the script and shell syntax.
7.1.2. Conditional script
The process script can also be defined in a complete dynamic manner using a if statement or any other expression evaluating to string value. For example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
params.aligner = 'kallisto'
process foo {
script:
if( params.aligner == 'kallisto' )
"""
kallisto --reads /some/data.fastq
"""
else if( params.aligner == 'salmon' )
"""
salmons --reads /some/data.fastq
"""
else
throw new IllegalArgumentException("Unknown aligner $params.aligner")
}
Exercise
Write a custom function that given the aligner name as parameter returns the command string to be executed. Then use this function as the process script body.
7.2. Inputs
Nextflow processes are isolated from each other but can communicate between themselves sending values through channels.
The input block defines which channels the process is expecting to receive inputs data from. You can only define one input block at a time and it must contain one or more inputs declarations.
The input block follows the syntax shown below:
input:
<input qualifier> <input name> [from <source channel>]7.2.1. Input values
The val qualifier allows you to receive data of any type as input. It can be accessed in the process script by using the specified input name, as shown in the following example:
1
2
3
4
5
6
7
8
9
10
num = Channel.from( 1, 2, 3 )
process basicExample {
input:
val x from num
"""
echo process job $x
"""
}
In the above example the process is executed three times, each time a value is received from the channel num and used to process the script. Thus, it results in an output similar to the one shown below:
process job 3
process job 1
process job 2| The channel guarantees that items are delivered in the same order as they have been sent - but - since the process is executed in a parallel manner, there is no guarantee that they are processed in the same order as they are received. |
7.2.2. Input files
The file qualifier allows the handling of file values in the process execution context. This means that
Nextflow will stage it in the process execution directory, and it can be access in the script by using the name specified in the input declaration.
1
2
3
4
5
6
7
8
9
10
reads = Channel.fromPath( 'data/ggal/*.fq' )
process foo {
input:
file 'sample.fastq' from reads
script:
"""
your_command --reads sample.fastq
"""
}
The input file name can also be defined using a variable reference as shown below:
1
2
3
4
5
6
7
8
9
10
reads = Channel.fromPath( 'data/ggal/*.fq' )
process foo {
input:
file sample from reads
script:
"""
your_command --reads $sample
"""
}
The same syntax it’s also able to handle more than one input file in the same execution. Only change the channel composition.
1
2
3
4
5
6
7
8
9
10
reads = Channel.fromPath( 'data/ggal/*.fq' )
process foo {
input:
file sample from reads.collect()
script:
"""
your_command --reads $sample
"""
}
Exercise
Write a script that merge all read files matching the pattern data/ggal/*_1.fq into a single
file. Then print the first 20 lines.
7.2.3. Combine input channels
A key feature of processes is the ability to handle inputs from multiple channels. However it’s important to understands how the content of channel and their semantic affect the execution of a process.
Consider the following example:
1
2
3
4
5
6
7
8
9
10
process foo {
echo true
input:
val x from Channel.from(1,2,3)
val y from Channel.from('a','b','c')
script:
"""
echo $x and $y
"""
}
Both channels emit three value, therefore the process is executed three times, each time with a different pair:
-
(1, a)
-
(2, b)
-
(3, c)
What is happening is that the process waits until there’s a complete input configuration i.e. it receives an input value from all the channels declared as input.
When this condition is verified, it consumes the input values coming from the respective channels, and spawns a task execution, then repeat the same logic until one or more channels have no more content.
This means channel values are consumed serially one after another and the first empty channel cause the process execution to stop even if there are other values in other channels.
What does it happen when not all channels have the same cardinality (i.e. they emit a different number of elements)?
For example:
1
2
3
4
5
6
7
8
9
10
process foo {
echo true
input:
val x from Channel.from(1,2)
val y from Channel.from('a','b','c','d')
script:
"""
echo $x and $y
"""
}
In the above example the process is executed only two time, because when a channel has no more data to be processed it stops the process execution.
| Note however that value channel do not affect the process termination. |
To better understand this behavior compare the previous example with the following one:
1
2
3
4
5
6
7
8
9
10
process bar {
echo true
input:
val x from Channel.value(1)
val y from Channel.from('a','b','c')
script:
"""
echo $x and $y
"""
}
Exercise
Write a process that is executed for each read file matching the pattern data/ggal/*_1.fa and
and use the same data/ggal/transcriptome.fa in each execution.
7.2.4. Input repeaters
The each qualifier allows you to repeat the execution of a process for each item in a collection, every time a new data is received. For example:
1
2
3
4
5
6
7
8
9
10
11
12
sequences = Channel.fromPath('*.fa')
methods = ['regular', 'expresso', 'psicoffee']
process alignSequences {
input:
file seq from sequences
each mode from methods
"""
t_coffee -in $seq -mode $mode
"""
}
In the above example every time a file of sequences is received as input by the process, it executes three tasks running a T-coffee alignment with a different value for the mode parameter. This is useful when you need to repeat the same task for a given set of parameters.
Exercise
Extend the previous example so a task is executed for each read file matching the pattern data/ggal/*_1.fa and repeat the same task both with salmon and kallisto.
7.3. Outputs
The output declaration block allows to define the channels used by the process to send out the results produced.
It can be defined at most one output block and it can contain one or more outputs declarations. The output block follows the syntax shown below:
output: <output qualifier> <output name> [into <target channel>[,channel,..]]
7.3.1. Output values
The val qualifier allows to output a value defined in the script context. In a common usage scenario,
this is a value which has been defined in the input declaration block, as shown in the following example::
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
methods = ['prot','dna', 'rna']
process foo {
input:
val x from methods
output:
val x into receiver
"""
echo $x > file
"""
}
receiver.println { "Received: $it" }
7.3.2. Output files
The file qualifier allows to output one or more files, produced by the process, over the specified channel.
1
2
3
4
5
6
7
8
9
10
11
process randomNum {
output:
file 'result.txt' into numbers
'''
echo $RANDOM > result.txt
'''
}
numbers.println { "Received: " + it.text }
In the above example the process randomNum creates a file named result.txt containing a random number.
Since a file parameter using the same name is declared in the output block, when the task is completed that
file is sent over the numbers channel. A downstream process declaring the same channel as input will
be able to receive it.
7.3.3. Multiple output files
When an output file name contains a * or ? wildcard character it is interpreted as a
glob path matcher.
This allows to capture multiple files into a list object and output them as a sole emission. For example:
1
2
3
4
5
6
7
8
9
10
11
12
13
process splitLetters {
output:
file 'chunk_*' into letters
'''
printf 'Hola' | split -b 1 - chunk_
'''
}
letters
.flatMap()
.println { "File: ${it.name} => ${it.text}" }
it prints:
File: chunk_aa => H File: chunk_ab => o File: chunk_ac => l File: chunk_ad => a
Some caveats on glob pattern behavior:
-
Input files are not included in the list of possible matches.
-
Glob pattern matches against both files and directories path.
-
When a two stars pattern
**is used to recourse across directories, only file paths are matched i.e. directories are not included in the result list.
Exercise
Remove the flatMap operator and see out the output change. The documentation
for the flatMap operator is available at this link.
7.3.4. Dynamic output file names
When an output file name needs to be expressed dynamically, it is possible to define it using a dynamic evaluated string which references values defined in the input declaration block or in the script global context. For example::
1
2
3
4
5
6
7
8
9
10
11
12
process align {
input:
val x from species
file seq from sequences
output:
file "${x}.aln" into genomes
"""
t_coffee -in $seq > ${x}.aln
"""
}
In the above example, each time the process is executed an alignment file is produced whose name depends
on the actual value of the x input.
7.3.5. Composite inputs and outputs
So far we have seen how to declare multiple input and output channels, but each channel was handling only one value at time. However Nextflow can handle tuple of values.
When using channel emitting tuple of values the corresponding input declaration must be declared with a set qualifier followed by definition of each single element in the tuple.
In the same manner output channel emitting tuple of values can be declared using the set qualifier
following by the definition of each tuple element in the tuple.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
reads_ch = Channel.fromFilePairs('data/ggal/*_{1,2}.fq')
process foo {
input:
set val(sample_id), file(sample_files) from reads_ch
output:
set val(sample_id), file('sample.bam') into bam_ch
script:
"""
your_command_here --reads $sample_id > sample.bam
"""
}
bam_ch.println()
Exercise
Modify the script of the previous exercise so that the bam file is named as the given sample_id.
7.4. When
The when declaration allows you to define a condition that must be verified in order to execute the process. This can be any expression that evaluates a boolean value.
It is useful to enable/disable the process execution depending the state of various inputs and parameters. For example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
params.dbtype = 'nr'
params.prot = 'data/prots/*.tfa'
proteins = Channel.fromPath(params.prot)
process find {
input:
file fasta from proteins
val type from params.dbtype
when:
fasta.name =~ /^BB11.*/ && type == 'nr'
script:
"""
blastp -query $fasta -db nr
"""
}
7.5. Directives
Directive declarations allow the definition of optional settings that affect the execution of the current process without affecting the semantic of the task itself.
They must be entered at the top of the process body, before any other declaration blocks (i.e. input, output, etc).
Directives are commonly used to define the amount of computing resources to be used or other meta directives like that allows the definition of extra information for configuration or logging purpose. For example:
1
2
3
4
5
6
7
8
9
10
process foo {
cpus 2
memory 8.GB
container 'image/name'
script:
"""
your_command --this --that
"""
}
The complete list of directives is available at this link.
Exercise
Modify the script of the previous exercise adding a tag directive logging the sample_id in the execution output.